Improved Visual Grounding through Self-Consistent Explanations [CVPR 2024]
Ruozhen Catherine He1, Paola Cascante-Bonilla1, Ziyan Yang1, Alexander C. Berg2, Vicente Ordóñez1,
1Rice University, 2UC Irvine
Abstract
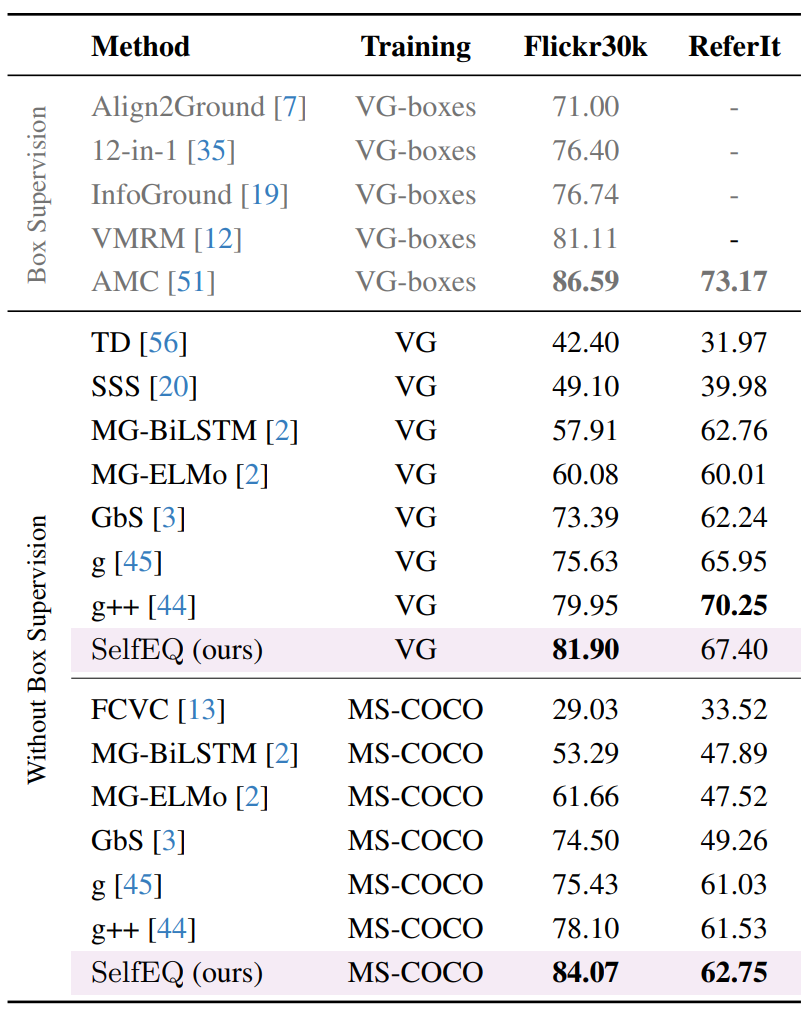
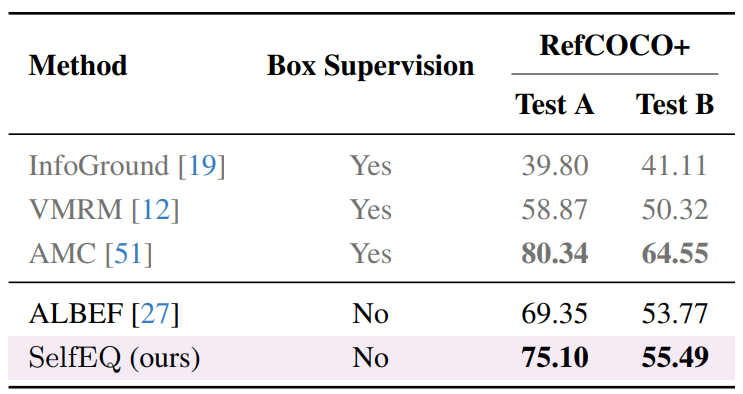
Vision-and-language models trained to match images with text can be combined with visual explanation methods to point to the locations of specific objects in an image. Our work shows that the localization --''grounding''-- abilities of these models can be further improved by finetuning for self-consistent visual explanations. We propose a strategy for augmenting existing text-image datasets with paraphrases using a large language model, and SelfEQ, a weakly-supervised strategy on visual explanation maps for paraphrases that encourages self-consistency. Specifically, for an input textual phrase, we attempt to generate a paraphrase and finetune the model so that the phrase and paraphrase map to the same region in the image. We posit that this both expands the vocabulary that the model is able to handle, and improves the quality of the object locations highlighted by gradient-based visual explanation methods (e.g. GradCAM). We demonstrate that SelfEQ improves performance on Flickr30k, ReferIt, and RefCOCO+ over a strong baseline method and several prior works. Particularly, comparing to other methods that do not use any type of box annotations, we obtain 84.07% on Flickr30k (an absolute improvement of 4.69%), 67.40% on ReferIt (an absolute improvement of 7.68%), and 75.10%, 55.49% on RefCOCO+ test sets A and B respectively (an absolute improvement of 3.74% on average).
Overview
In order to improve the ability of vision-and-language models to perform localization, many methods have incorporated further finetuning with either box or segment annotations, or rely on pretrained object detectors or box proposal networks.
Our work instead aims to improve the localization capabilities of models trained only on image-text pairs through weak supervision.
But, how can we improve the ability of a model to localize objects without access to object location annotations?
Consider the example in Figure below, where a model is tasked with pointing to the location of the object frisbee in this image.
The baseline model succeeds at finding the object but is unsuccessful at locating the object when prompted with the equivalent but more generic name disc.
Regardless of the ability for the base model to find either of these, the visual explanations for these two prompts should be the same since the query refers to the very same object in both cases.
Our work exploits this property by first generating paraphrases using a large language model and then proposing a weakly-supervised Self-consistency EQuivalence Tuning (SelfEQ) objective
that encourages consistent visual explanations between paraphrased input text pairs that refer to the same object or region in a given image.

Method
Given a base pre-trained vision-and-language model purely trained on image-text pairs such as ALBEF, SelfEQ tunes the model so that for a given input image and text pair, the visual attention map extracted using GradCAM produces a similar visual attention map when provided with the same image and a text paraphrase. The figure below provides an overview of our method. Another contribution of our work consists in exploiting a large language model (LLM) to automatically generate paraphrases for existing datasets such as Visual Genome that contains textual descriptions of individual objects and regions, or MS-COCO and CC3M that contain global image descriptions. We find that SelfEQ not only expands the vocabulary of objects that the base model is able to localize but more importantly, improves the visual grounding capabilities of the model.
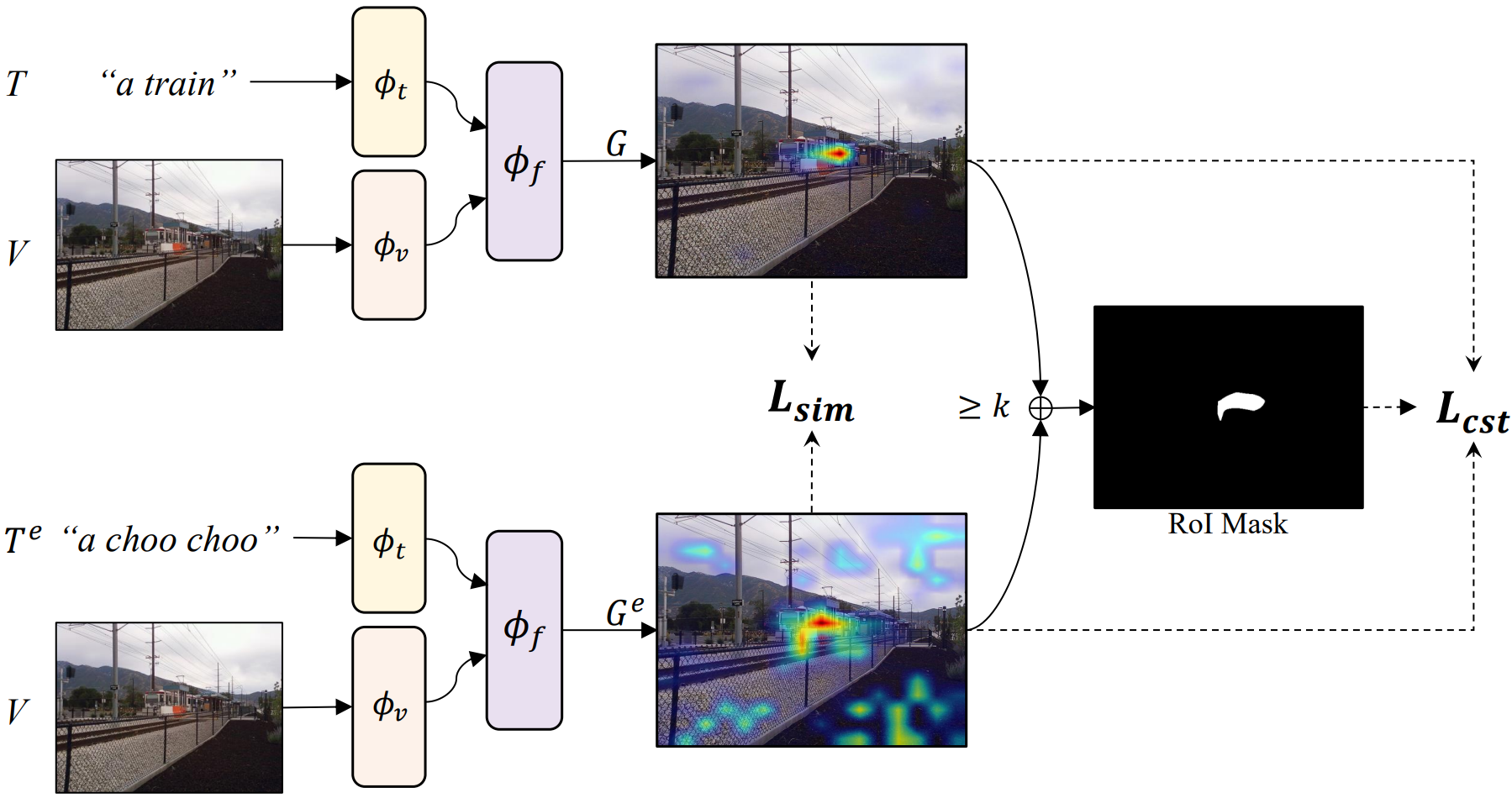
Overview of our proposed weakly-supervised Self-consistency EQuivalence tuning objective. We input image-text and image-paraphrase pairs ⟨V, T⟩ and ⟨V, Te⟩ to our base pre-trained vision-and-language model. We then obtain gradient-based visual explanations ⟨G, Ge⟩ and compute a similarity loss between them. We also define an overlapping region of interest mask and encourage the model to predict consistently high saliency scores within this mask for each input pair.
Experimental Results
Our resulting model obtains the best performance on the task of weakly-supervised visual grounding compared to most methods under this setting and is comparable to several prior works that rely on some of box supervision. Moreover, our qualitative results show that our method can handle paraphrases and a larger vocabulary without the needed to increment the training dataset significantly.




BibTeX
@article{he2023improved,
title={Improved Visual Grounding through Self-Consistent Explanations},
author={He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C and Ordonez, Vicente},
journal={arXiv preprint arXiv:2312.04554},
year={2023} }