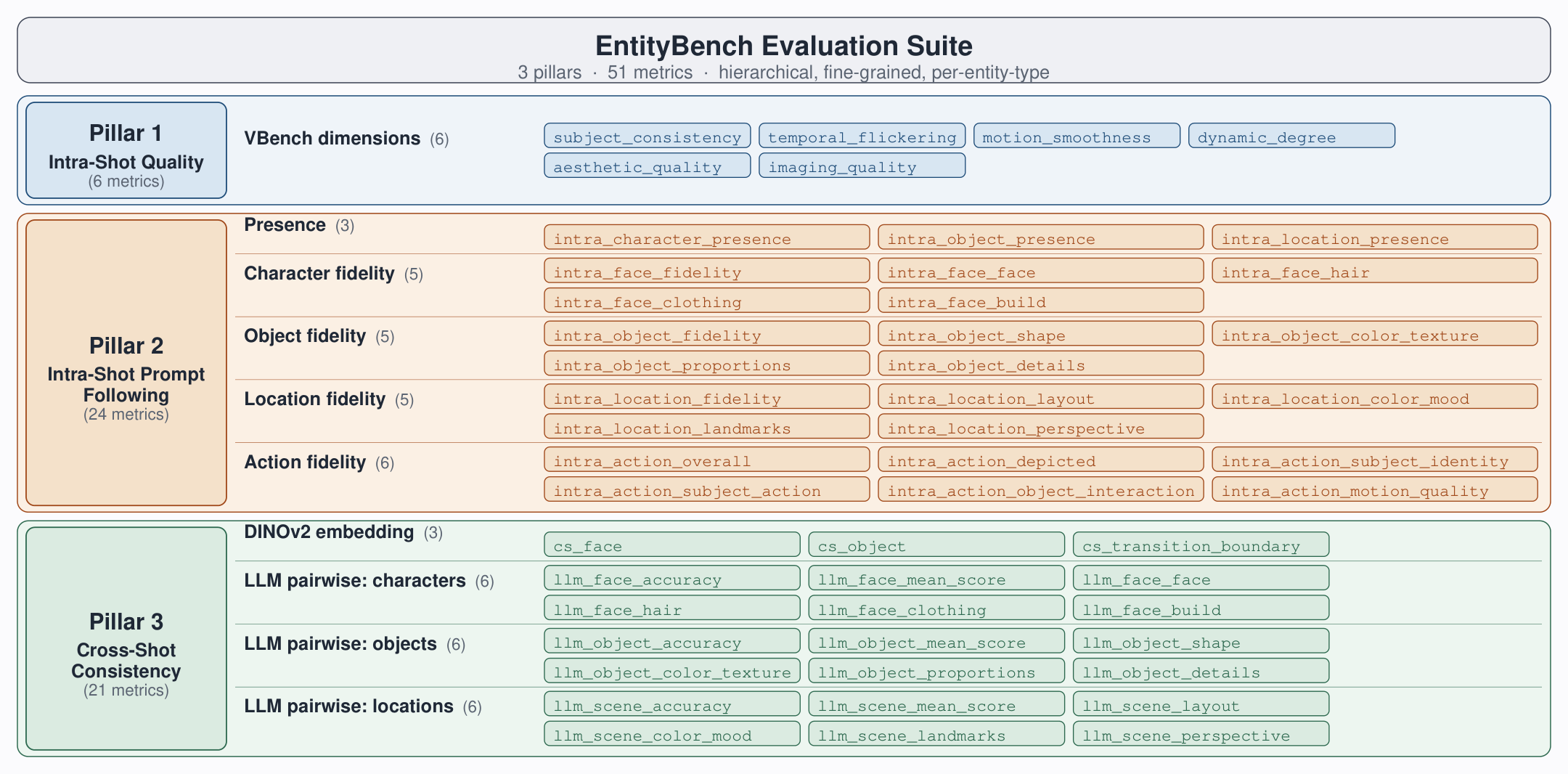
The Benchmark
A Long-Range Cross-Shot Entity Memory Test
EntityBench scripts are derived from real narrative media, then enriched and validated by LLMs into generation-ready prompts. Each shot ships with an explicit entity_schedule naming the characters, objects, and locations expected to appear, along with cut and continuation transition flags. The three difficulty tiers separate long-range memory load from intra-shot complexity: hard-tier episodes hold per-shot composition roughly constant while pushing recurrence gaps past 30 shots and entity-slot re-appearance rates above 80%.
140
Episodes
2,491
Shots
3,718
Unique entities
68.6%
Re-appearance rate
48
Max recurrence gap
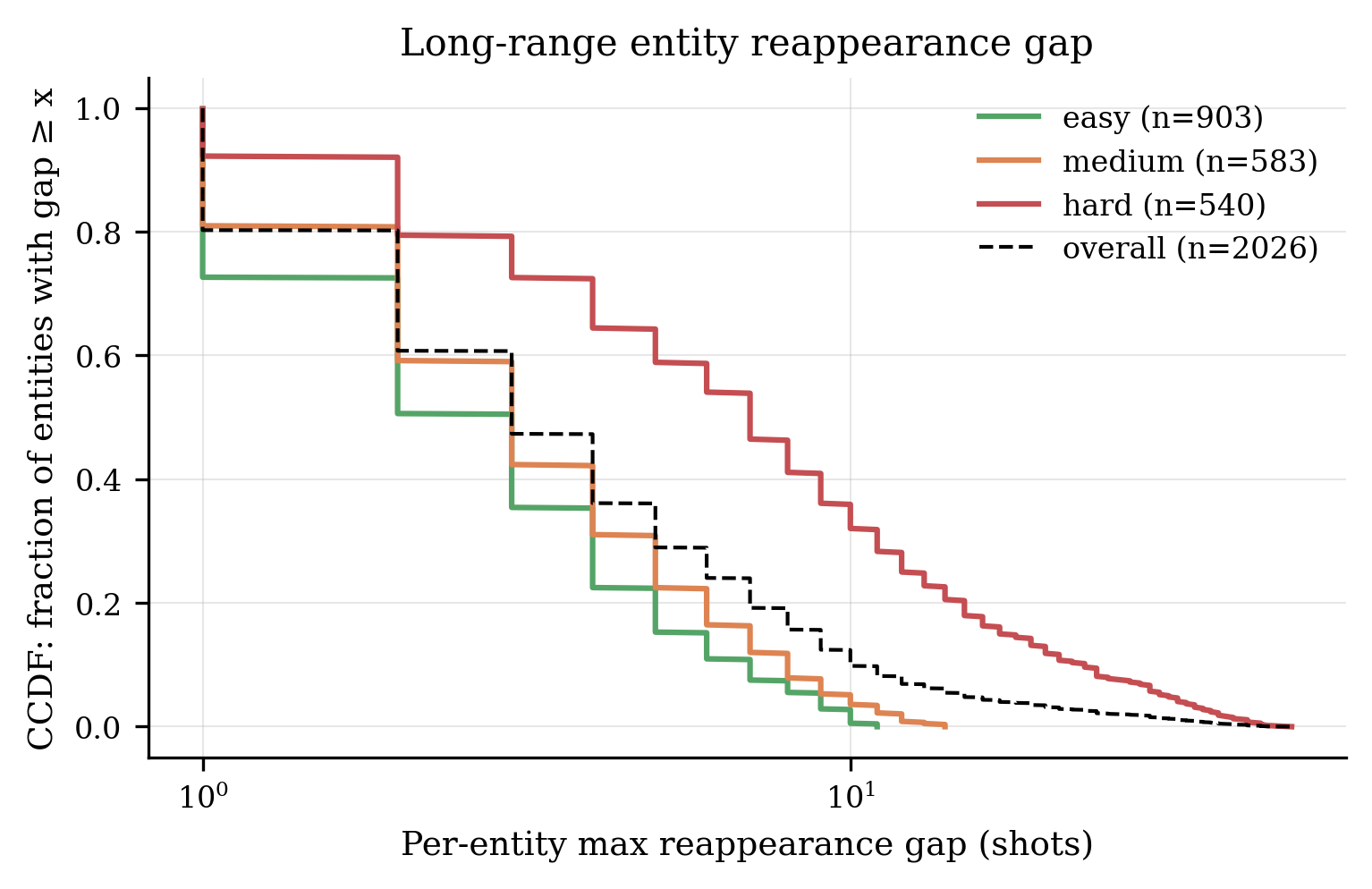
Recurrence-gap CCDF. The hard tier carries a heavy tail past 30 intervening shots — a long-range stress test absent from prior benchmarks.
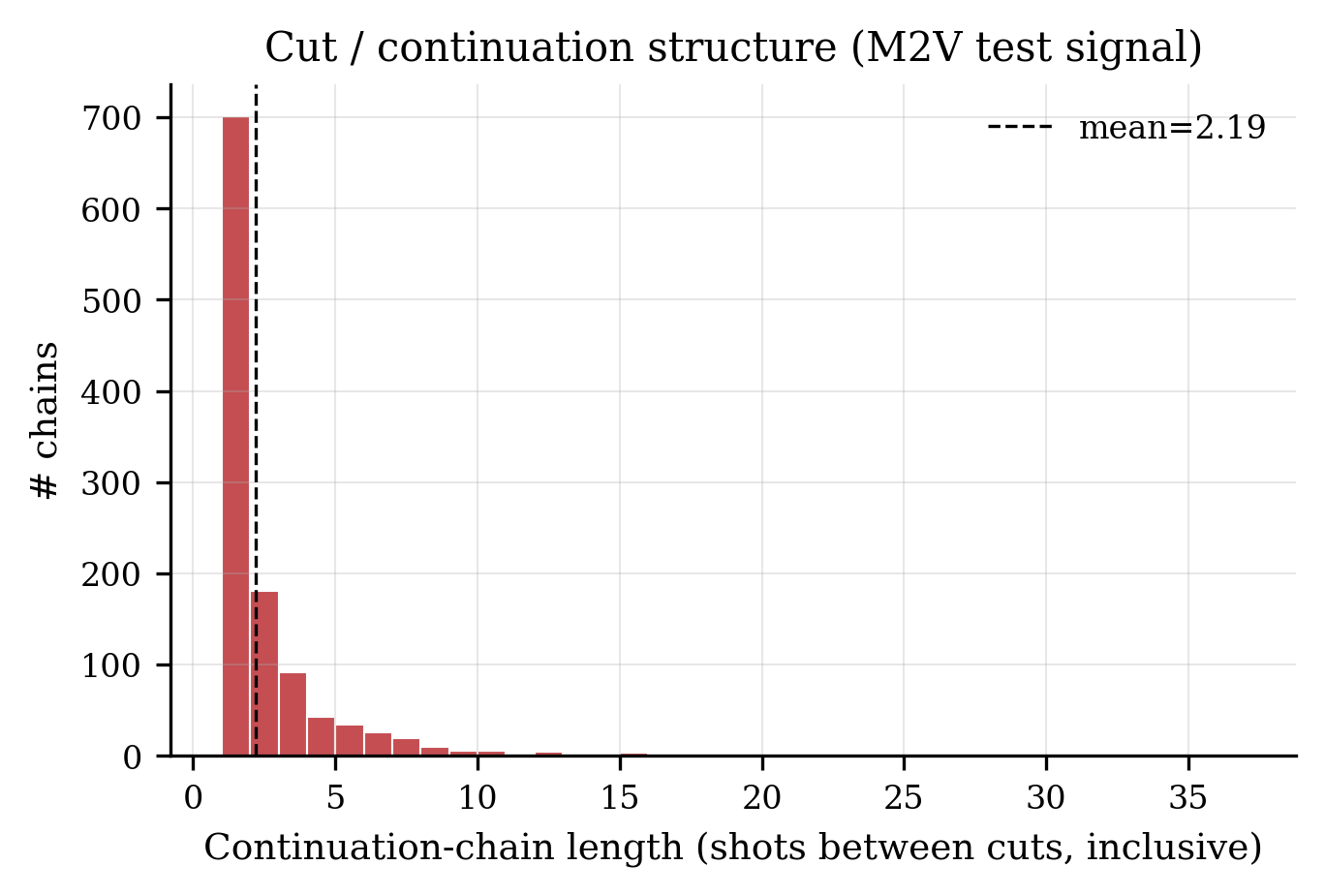
Cut / continuation structure. Chains of consecutive non-cut shots extend up to 36, providing transition-fidelity signal at scale.
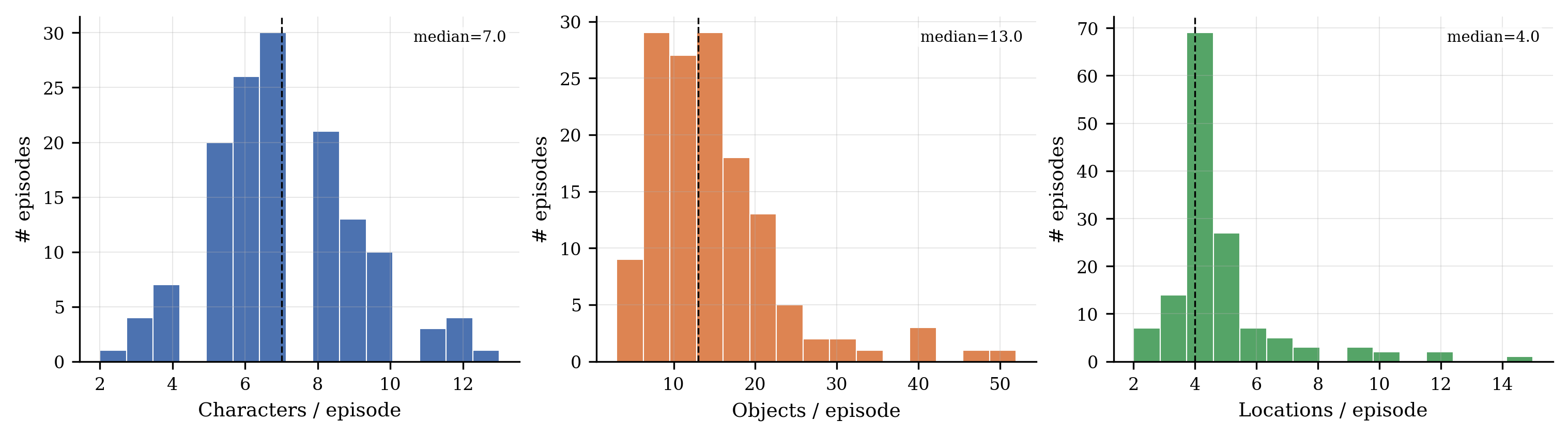
Per-episode entity counts. An average episode declares 7 characters, 5 locations, and 15 objects.
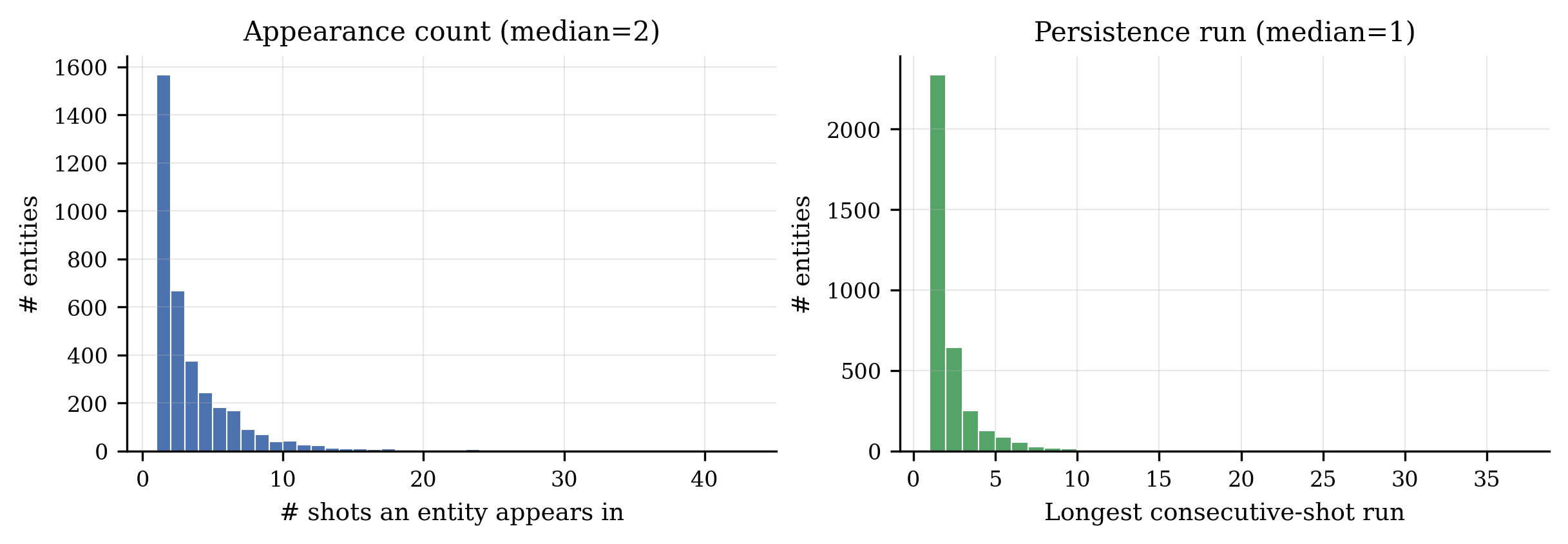
Per-entity persistence. Most entities appear in 2 shots; anchor entities sustain runs of up to 9 consecutive shots.
Characters are tested most aggressively: 80.3% of every character slot in the benchmark must be rendered from memory, not from a prompt-level description.